This chapter describes the character encoding concepts for the
VT220 when operating in text mode. The chapter also describes the
VT220 character sets and provides an overview of the control
functions. You must have a basic understanding of the coding
concepts described in this chapter before using the control
functions described in Chapters 3 and 4.
2.2 Coding Standards
The VT220 uses an 8-bit character encoding scheme and a 7-bit code
extension technique that are compatible with the following ANSI
and ISO standards. ANSI (American National Standards Institute)
and ISO (International Organization for Standardization) specify
the current standards for character encoding used in the
communications industry.
Standard
Description
ANSI X3.4 – 1977
American Standard Code for Information
Interchange (ASCII)
ISO 646 – 1977
7-Bit Coded Character Set for
Information Processing Interchange
ANSI X3.41 – 1974
Code Extension Techniques for Use with
the 7-Bit Coded Character Set of
American National Code Information
Interchange
ISO Draft International Standard 2022.2
7-Bit and 8-Bit Coded Character Sets – Code Extension Techniques
ANSI X3.32 – 1973
Graphic Representation of the Control Characters of American National Code for Information Interchange
ANSI X3.64 – 1979
Additional Controls for Use with
American National Standard for Information Interchange
ISO Draft International Standard 6429.2
Additional Control Functions for Character Imaging Devices
2.3 Code Table
A code table is a convenient way to represent 7-bit and 8-bit
characters, because you can see groupings of characters and their
relative codes clearly.
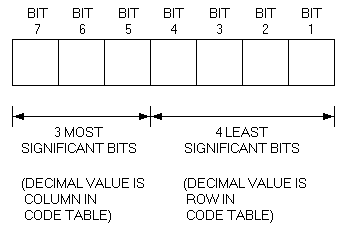
2.3.1 7-Bit ASCII Code Table
Table 2-1 is the 7-bit ASCII code table. There are 128 positions
corresponding to 128 character codes, arranged in a matrix of 8
columns and 16 rows.
Each row represents a possible value of the four least significant
bits of a 7-bit code (Figure 2-1). Each column represents a
possible value of the three most significant bits.
Table 2-1 shows the octal, decimal, and hexadecimal code for each
ASCII character. You can also represent any character by its
position in the table. For example, the character H (column 4, row
8) can be represented as 4/8. This column/row notation is used to
represent characters and codes throughout this manual. For
example:
1/11 2/3 3/6
ESC # 6
means that the ESC character is at column 1, row 11; the character
# is at column 2, row 3; and the character 6 is at column 3, row
6.
The VT220 processes received characters based on two character
types defined by ANSI, graphic characters and control characters.
Graphic characters are characters you can display on a video
screen. The ASCII graphic characters are in positions 2/1 through
7/14 of Table 2-1. They include all American and English
alphanumeric characters, plus punctuation marks and various text
symbols. Examples are: C, n, ", !, +, and $ (the English pound
sign is not an ASCII graphic character).
Control characters are not displayed. They are single-byte codes
that perform specific functions in data communications and text
processing. The ASCII control characters are in positions 0/0
through 1/15 (columns 0 and 1) of Table 2-1. The SP character
(space, 2/0) may act as a graphic character or a control
character, depending on the context. DEL (7/15) is always a
control character.
Control character codes and functions are standardized by ANSI.
Examples of ASCII control characters with their ANSI-standard
mnemonics are: CR (carriage return), FF (form
feed), CAN (cancel).
In general, the conventions for 7-bit character encoding also
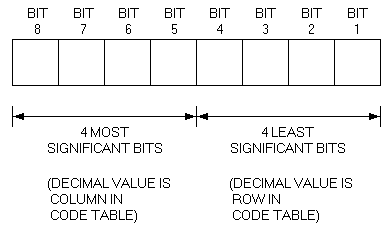
apply to 8-bit character encoding for the VT220. Table 2-2 shows
the 8-bit code table. It has twice as many columns as the 7-bit
table, because it contains 256 (versus 128) code values.
As with the 7-bit table, each row represents a possible value of
the four least significant bits of an 8-bit code (Figure 2-2).
Each column represents a possible value of the four most
significant bits.
All codes on the left half of the 8-bit table (columns 0 through
7) are 7-bit compatible; their eighth bit is not set, and can be
ignored or assumed to be 0. You can use these codes in a 7-bit or
an 8-bit environment. All codes on the right half of the table
(columns 8 through 15) have their eighth bit set. You can use
these codes only in an 8-bit compatible environment.
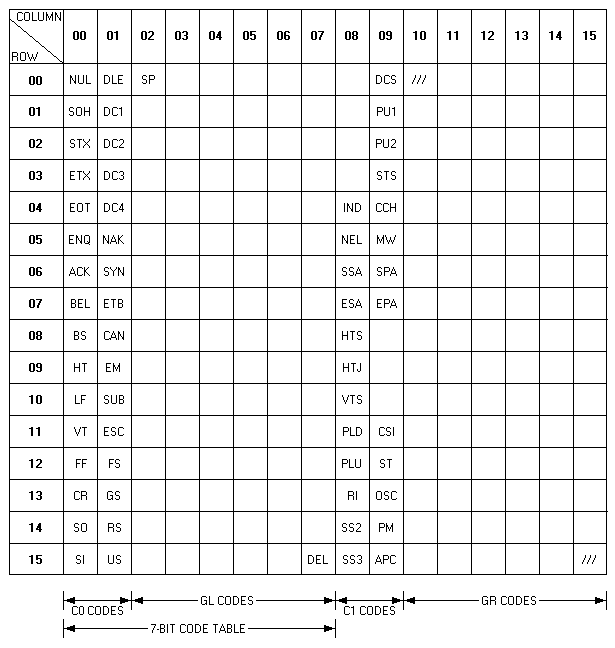
The 8-bit code table (Table 2-2) has two sets of control
characters, C0 (control zero) and C1 (control one). The table also
has two sets of graphic characters, GL (graphic left) and GR
(graphic right).
On the VT220, the basic functions of the C0 and C1 codes are
defined by ANSI. C0 codes represent the ASCII control characters
described earlier. The C0 codes are 7-bit compatible. The C1 codes
represent 8-bit control characters that let you perform additional
functions beyond those possible with the C0 codes. You can only
use C1 codes directly in an 8-bit environment. Some C1 code
positions are blank, because their functions are not yet
standardized.
NOTE: The VT220 does not recognize all C0 and
C1 codes. Chapter 4 identifies and
describes the codes it does recognize;
all others are simply ignored. (That is,
no action is taken).
The GL and GR sets of codes are reserved for graphic characters.
There are 94 GL codes in positions 2/1 through 7/14, and 94 GR
codes in positions 10/1 through 15/14. By ANSI standards,
positions 10/0 and 15/15 are not used. You can use GL codes in
7-bit or 8-bit environments. You can use GR codes only in an 8-bit
environment.
Table 2-2 8-Bit Code TableFigure 2-2 8-Bit Code
2.4 Character Sets
You cannot change the functions of the C0 or C1 codes. However,
you can map different sets of graphic characters into the GL
and/or GR codes. The sets are stored in the terminal as a graphic
repertoire. But you cannot use these graphics character sets until
you map them into the GL or GR codes. Chapter 4 describes the
commands for mapping graphic character sets into GL or GR.
The terminal's graphic repertoire consists of the following
character sets, described in the following sections.
DEC multinational (consists of the ASCII graphics set and
DEC supplemental graphics set)
DEC special graphics
National replacement character (NRC) sets
Down-line-loadable
2.4.1 DEC Multinational Character Set
By factory default, when you power up or reset the terminal, the
DEC multinational character set (Table 2-3) is mapped into the
8-bit code matrix (columns 0 through 15).
The 7-bit compatible left half of the DEC multinational set is the
ASCII graphics set. The C0 codes are the ASCII control characters,
and the GL codes are the ASCII graphics set.
The 8-bit compatible right half of the DEC multinational set
includes the C1 8-bit control characters in columns 8 and 9. The
GR codes are the DEC supplemental graphics set. The DEC
supplemental graphics set has alphabetic characters with accents
and diacritical marks that appear in the major Western European
alphabets. It also has other symbols not included in the ASCII
graphics set.
The terminal can work with over a dozen national (Western
European) keyboards. All keyboards assume the default DEC
multinational character set mapping. The code descriptions in the
rest of this manual also assume this mapping. Various characters
from the DEC supplemental graphics set appear as standard
(printing character) keys on different keyboards.
The DEC supplemental graphics character set is not available in
VT52 and VT100 modes.
Table 2-3 DEC Multinational Character Set (Left Half – C0 and GL Codes)Table 2-3 DEC Multinational Character Set (Right Half – C1 and GR Codes)
2.4.2 DEC Special Graphics Character Set
The terminal's graphic repertoire includes the DEC special
graphics set (also known as the VT100 line drawing character set).
This character set (Table 2-4) has about two-thirds of the ASCII
graphic characters. It also has special symbols and short line
segments. The line segments let you create a limited range of
pictures while still using text mode.
Commands described in Chapter 4 let you map the DEC special
graphics set into either GL or GR, replacing either the ASCII
graphics set or the DEC supplemental graphics set. Digital
recommends that you switch between ASCII and DEC special graphics
in GL, because the latter has most of the ASCII graphic
characters. Also, this mapping is compatible with a VT100
terminal.
Table 2-4 DEC Special Graphics Character Set
2.4.3 National Replacement Character Sets (NRC sets)
The terminal's graphic character repertoire includes national
replacement character sets (Tables 2-5 through 2-15). These sets
are available when you select national mode. Only one national
character set is available for use at any one time. The NRC set
used depends on the keyboard selection in set-up as outlined
below.
Table 2-5 British NRC Set (British Keyboard Selection)Table 2-6 Dutch NRC Set (Dutch Keyboard Selection)Table 2-7 Finnish NRC Set (Finnish Keyboard Selection)Table 2-8 French NRC Set (Flemish and French/Belgian Keyboard Selections)Table 2-9 French Canadian NRC Set (French Canadian Keyboard Selection)Table 2-10 German NRC Set (German Keyboard Selection)Table 2-11 Italian NRC Set (Italian Keyboard Selection)Table 2-12 Norwegian/Danish NRC Set (Danish and Norwegian Keyboard Selections)Table 2-13 Spanish NRC Set (Spanish Keyboard Selection)Table 2-14 Swedish NRC Set (Swedish Keyboard Selection)Table 2-15 Swiss NRC Set (Swiss/French and Swiss/German Keyboard Selections)
2.4.4 Down-Line-Loadable Character Set
The terminal provides for a 94-character down-line-loadable
graphic character set. You can define this character set and map
it into either GL or GR, as described in Chapter 4. This feature
is available only in VT200 mode.
2.5 Control Functions
You use control functions in your program to specify how the
terminal should handle data. There are many uses for control
functions. Here are some examples.
Move the cursor on the display.
Delete a line of text from the display.
Change character and line attributes.
Change graphic character sets.
Set the terminal operating mode.
You can use all control functions in text mode and express them as
single-byte or multibyte codes.
The single-byte codes are the C0 and C1 control characters. Your
program can perform a limited number of functions using C0
characters. C1 characters give you a few more functions, but your
program can use them directly only in an 8-bit environment.
Multibyte control codes represent far more functions, because they
have more possible code combinations. These codes are called
escape sequences, control sequences, and device control strings.
Some sequences are ANSI standardized and used throughout the
industry; others are private sequences created by manufacturers
like Digital for specific families of products. Private sequences,
like ANSI standardized sequences, follow ANSI standards for
character code composition.
2.5.1 Escape Sequences
An escape sequence starts with the C0 character ESC (1/11),
followed by one or more ASCII graphic characters. For example,
1/11 2/3 3/6
ESC # 6
is an escape sequence that changes the current line of text to
double-width characters.
Because escape sequences use only 7-bit characters, you can use
them in 7-bit or 8-bit environments.
NOTE: When using escape or control sequences,
remember that it is the code that
defines a sequence -- not the graphic
representation of the characters. The
characters are shown for readability
only and presume the DEC multinational
character set mapping (ASCII graphics
set in GL and DEC supplemental graphics
set in GR).
One important use of escape sequences is extending the capability
of 7-bit control functions. ANSI lets you use 2-byte escape
sequences as 7-bit code extensions to express each of the C1
control codes. This is a valuable feature when your application
must be compatible with a 7-bit environment. For example, the C1
characters CSI, SS3, and IND can be expressed as follows.
C1 Character
7-Bit Code Extension Equivalent (Escape Sequence)
9/11
CSI
1/11 5/11
ESC [
8/15
SS3
1/11 4/15
ESC O
8/4
IND
1/11 4/4
ESC D
In general, you can use the above code extension technique in two
ways.
You can express any C1 control character as a 2-character
escape sequence whose second character has a code that is
40 (hexadecimal) and 64 (decimal) less than that of the
C1 character.
You can make any escape sequence whose second character
is in the range of 4/0 through 5/15 one byte shorter by
removing the ESC and adding 40 (hexadecimal) to the code
of the second character. This generates an 8-bit control
character.
2.5.2 Control Sequences
A control sequence starts with CSI (9/11), followed by one or more
ASCII graphic characters. But CSI (9/11) can also be expressed as
the 7-bit code extension ESC [ (1/11, 5/11). So you can express
all control sequences as escape sequences whose second character
code is [ (5/11). For example, the following two sequences are
equivalent sequences that perform the same function. (They cause
the display to use 132 columns per line rather than 80).
9/11 3/15 3/3 6/8
CSI ? 3 h
1/11 5/11 3/15 3/3 6/8
ESC [ ? 3 h
Whenever possible, you should use CSI instead of ESC [ to
introduce a control sequence. CSI uses one less byte than ESC [,
so you gain processing speed. However, you can only use a sequence
starting with CSI in an 8-bit environment (because CSI is a C1
control character).
2.5.3 Device Control Strings
A device control string (DCS) is a delimited string of characters
used in a data stream as a logical entity for control purposes. It
consists of an opening delimiter (a device control string
introducer), a command string (data), and a closing delimiter (a
string terminator).
You use device control strings to down-line-load character sets
and definitions for user-defined keys.
The VT220 uses the following device control string format.
9/0 DCS
.......... Data
9/12 ST
Device Control String (opening delimiter)
UDK
Character Set
String Terminator (closing delimiter)
DCS is an 8-bit control character. You can also express it as ESC
P (1/11, 5/0) when coding for a 7-bit environment.
ST is an 8-bit control character. You can also express it as ESC \
(1/11, 5/12) when coding for a 7-bit environment.
2.6 Working with 7-Bit and 8-Bit Environments
There are two requirements for using the terminal's 8-bit
character set. Your program and communication environment must be
8-bit compatible, and the terminal must operate in a VT200 mode.
When operating in VT100 or VT52 mode, you are limited to working
in a 7-bit environment. The following sections describe
conventions that apply in VT200 mode.
2.6.1 Conventions for Codes Received by the Terminal
The terminal expects to receive character codes in a form
consistent with 8-bit coding. Your application can use the C0 and
C1 control codes, as well as the 7-bit C1 code extensions, if
necessary. The terminal always interprets these codes correctly.
Chapter 4 describes all code extensions you may need to use, and
their equivalent C1 control codes.
When your program sends GL or GR codes, the terminal interprets
the codes according to the graphic character mapping currently in
use. The factory-default mapping (which is set when you power up
or reset the terminal) is the DEC multinational character set.
This mapping assumes the current terminal mode is one of the VT200
modes.
2.6.2 Conventions for Codes Sent by the Terminal
Codes sent by the terminal to a program can come directly from the
keyboard or in response to commands issued from the host
(application program or operating system). In a VT200 mode, the
terminal always sends all GL and GR graphic codes to the
application exactly as they are generated, regardless of whether
the application handles 8-bit codes correctly or not. If, however,
a 7-bit communications line is used, C1 controls are sent as
escape sequences and the terminal does not allow the generation of
8-bit graphic codes.
Most function keys on the keyboard generate multibyte control
codes. Many of these codes start with either CSI (9/11) or SS3
(8/15), which are C1 characters. If your application environment
cannot handle 8-bit codes, you can make the terminal automatically
convert all C1 codes to their equivalent 7-bit code extensions
before sending them to the application. To convert C1 codes, you
use the DECSCL commands described in Chapter 4.
By default, the terminal is set to automatically convert all C1
codes sent to the application to 7-bit code extensions. However,
to ensure the correct mode of operation, always use the
appropriate DECSCL commands described in Chapter 4.
NOTE: New programs should accept both 7-bit
and 8-bit forms of the C1 controls.
2.7 Display Controls Mode
The terminal has a display controls mode that lets you display
control codes as graphic characters for debugging purposes (rather
than executing them). You can select this mode by changing the
"Interpret/Display Controls" field in the Set-Up Display screen.
You cannot use an escape sequence or invoke this mode from the
host computer.
When the terminal is in a VT200 mode, selecting the set-up
"Display Controls" field temporarily loads C0, GL, C1, and GR as
shown in Table 2-16. All characters are displayed in the font
shown for C0, GL, C1, and GR.
When the terminal is in a VT52 or VT100 mode, selecting the set-up
"Display Controls" field temporarily loads C0 and GL as shown in
Table 2-16. All characters are displayed in the font shown for C0
and GL. (C1 and GR are meaningless in VT52 or VT100 modes).
When you select the "Display Controls" field, the terminal
displays all control functions and prevents most from executing.
There are only two exceptions. LF, FF, and VT cause a new line (CR
LF), and XOFF (DC3) and XON (DC1) maintain flow control if
enabled. LF, FF, and VT are displayed before CRLF is executed, and
DC1 and DC3 are displayed after execution.
Table 2-16 Display Controls Font (Left Half)Table 2-16 Display Controls Font (Right Half)